Como criei um projeto de Business Intelligence baseado nas minhas finanças pessoais (Parte 2)
Vimos que na primeira parte nós começamos o projeto, falei sobre algumas definições teóricas necessárias, desenvolvemos todo o levantamento de requisitos e levantamos a modelagem do nosso DW, agora vamos partir para a carga de dados desse Data Warehouse.
Passo 3: criação do ETL
Essa é a etapa no qual vamos extrair os dados do sistema de origem, fazer as transformações desses dados para seguir as regras de negócios e vamos carregar esses dados no nosso DW. Como falamos no passo anterior, o DW é o banco de dados que mantém os dados já organizados para a análise, onde os dados se encontram estruturados e livres de erros, por esses e mais alguns motivos o ideal conectar a ferramenta de visualização ao banco de dados DW, assim vamos usar a ferramenta de integração de dados para preparar esses DW e vamos fazer em três etapas, sendo elas:
- Extrair os dados da origem, a ferramenta de ETL fica responsável por extrair os dados da origem, seja qual fonte for;
- Transformar os dados, após a extração dos dados, a ferramenta de ETL se responsabiliza por transformar os dados aplicando as regras de negócio, como filtros, ordenações e verificações;
- Carregar os dados, com os dados transformados, a ferramenta de ETL carrega os dados no DW;
Uma das características de um DW é que ele não é volátil, isso faz que qualquer dado que esteja inserido não deva ser alterado, mas como vamos verificar se, antes de entrar no DW, esteja em conformidade com as regras de negócios? Vamos usar as tabelas temporárias, ou stage, que é um banco de dados que vamos usar para fazer esses tipos de verificações e deixar tudo certo para a carga no DW. Aqui iremos usar a ferramenta open-source Pentaho Community.
Tabelas temporárias (Stages)
As tabelas temporárias são tabelas sem ligações nenhuma, elas praticamente recebem os dados da extração do sistema de origem, assim podemos programar um horário específico para que a ferramenta de ETL consulte o sistema de origem e envia os dados para a nossa stage e com isso diminuímos a concorrência de acesso na origem. Sabemos que temos quatro dimensões e uma fato, mas a dimensão de tempo é um caso a parte que irei explicar melhor mais a frente, então temos três dimensões e uma fato, portanto teremos quatro tabelas temporárias. A ideia é a seguinte, essas tabelas terão o campo de origem onde será carregado com os campos extraídos da origem e o campo transformado ao seu lado, esse campo transformado será carregado após o campo origem ser tratado, por exemplo, o campo NM_PRODUTO_ORIGEM verifica se está nulo, caso esteja aplica alguma regra, assim é para todas as tabelas stages.
Os campos das tabelas stages seguirão com a nomenclatura padrão que criamos no DW, mas para os nomes das tabelas terá um prefixo ST_NOME_DA_TABELA, por exemplo ST_PRODUTO. Assim temos as seguintes tabelas:

Podemos ver que as tabelas não têm ligações entre si, fazendo que podemos manipular elas sem restrições de chaves estrangeiras, também vemos que o campo da chave primária é só um campo de apoio para podermos fazer a atualização da mesma tabela. Vale mencionar que para cada execução do processo as tabelas stages são truncadas, todos os dados são apagados, antes de iniciar a carga dessas tabelas. Vamos dividir nosso processo de ETL para cada etapa mencionada acima, então para a etapa de extração de dados iremos chamar de ETL1, para a transformação dos dados de ETL2 e para a carga dos dados será ETL3. Nós já conhecemos o sistema de origem e o sistema de destino, o DW, com isso temos que carregar quatro dimensões e uma fato, primeiramente vamos fazer a carga das dimensões e após isso vamos carregar a fato, essa sequência deve ser padrão, pois a fato usará dados que estarão nas dimensões, sem eles a carga resultará em erros de referência de chaves. O Pentaho trabalha de uma forma onde devemos inserir uma linha própria para ele em todas as dimensões, ele a usa para fazer as verificações de SCD, essa linha tem a chave primária igual a 0, para campos numéricos o valor é -1, para campos de caracteres o valor será Não Informado e para data temos o ano 1900, mês 01 e dia 01.
Dimensão de Tempo
A dimensão de tempo eu fiz um pouco diferente, a dimensão não tem um processo de ETL específico, podemos sim criar um para isso, mas escolhi uma forma mais fixa, criei ela a partir de um script SQL que faz a criação de toda a hierarquia.

Após a criação da tabela dimensão, é necessário a carga completa dessa dimensão, o script SQL no qual eu usei é o seguinte, para acessar ao comando, clique aqui.
Nossa tabela dimensão tempo está criada e carregada com as datas com inicio no ano de 2018 até o ano de 2028. Sei disso porque na instrução da data inicial de carga eu coloquei 3652 dias, que é aproximadamente 10 anos.
Dimensão de Produto
Para essa dimensão devemos extrair os produtos com a sua categoria, subcategoria e marca do nosso sistema de origem. Sabemos que essas tabelas na origem são tabelas diferentes, portanto devemos fazer, de alguma forma, recuperar o produto e olhar para essas tabelas e trazer essas informações. Precisamos disso pois a nossa dimensão espera esses dados serem carregados nela, como a imagem abaixo mostra.

Sabemos que no sistema de origem a tabela Produto recebe as chaves das tabelas de categoria, subcategoria e marca assim podemos passar tabela por tabela para recuperar o nome de cada um desses e carregar ela na nossa tabela de stage.

Esse é o processo de ETL1 no qual eu pensei e desenvolvi para a extração dos dados da origem e na carga de nossa stage, explicação de cada step que temos ali: No primeiro step, 1. Tabela Produto Origem, é onde há uma consulta em SQL na nossa origem extraindo os campos que necessito para fazer o processo.
Assim ela retorna a chave primária da tabela Produto o nome do produto e também os valores das chaves estrageiras da categoria, subcategoria e marca. E assim podemos prosseguir com os steps 2, 3 e 4. Os steps 2, 3 e 4 é uma LookUp nas tabelas que leva o nome do step, esse processo compara os campos chaves estrangeiras vindos da step de 1 com as chaves primárias das tabelas em questão, retornando o nome necessário para a nossa dimensão. Assim conseguimos recuperar o nome do produto, o nome da categoria, o nome da subcategoria e o nome da marca, falta somente os steps que são responsáveis por carregar essas informações na stage. O step 5 recupera a data do atual do sistema, assim temos a informação de qual foi a data da carga na tabela stage, o step 6 gera a sequência de apoio para a tabela de stage por onde iremos controlar a atualização da mesma. E por último, o step 7, que faz a carga dos dados vindo dos steps anteriores à ele na tabela stage. Na imagem temos uma prévia de alguns registros que serão carregados em nossa tabela stage.

Como disse anteriormente, os campos de origem serão carregados nos campos que tem o _ORIGEM no final do seu nome, para assim no ETL2 fazermos as verificações que desejarmos. Bom, no ETL2 é onde comumente usado para as aplicações das regras de negócios, portanto aqui é onde devemos tratar os dados, como a limpeza e a transformação dos dados. Essa parte deve ser entendida no passo de levantamento dos requisitos, assim, nesse caso, não existe regras específicas, mas aqui devemos transformar alguns dados para se adequar ao DW. Os tipos dos campos da nossa tabela ST_PRODUTO são todos do tipo varchar, o nosso DW alguns campos esperam que venham no tipo númerico, vamos fazer essa tranformação. Com os nossos dados extraidos e carregados na nossa tabela temporária, vamos partir para o ETL2, onde iremos fazer transformação dos dados para se adequar às nossas regras de negócio.

Então temos que, no primeiro step, 1. Extrai dados da Stage, é feito uma consulta na tabela stage retornando os dados de origem já carregados no ETL1.
No segundo step, 2. Transforma dados, seleciona os códigos origens de categoria, subcategoria, marca e produto para fazer a transformação de varchar para inteiro. O terceiro step, 3. Transforma nomes, é responsável por colocar os nomes dos produtos, categorias, subcategorias e marca em minúsculo e as letras iniciais maiúsculas. O step 4 recupera a data do atual do sistema, assim temos a informação de qual foi a data da alteração na tabela stage e no quinto step, é feito o update da tabela com os novos dados transformados nos campos desejados, aqueles sem o _ORIGEM.

Após o processo do ETL2, temos o resultado acima, onde podemos ver que os dados já estão processados e transformados, iremos agora dar início ao nosso ETL3 para carregar o nosso DW.

O processo acima é o do ETL3, a ideia é recuperar os dados já transformados do ETL2 dos campos, verificar se algum campo está nulo e transformar os dados pré-definidos e fazer a carga no banco de dados DW. Então, no primeiro step temos a extração dos dados da tabela temporária, no segundo step, 2. Transforma dados nulos, faz a verificação e caso algum campo esteja nulo irá substituir por dados pré-definidos, O step 5 recupera a data do atual do sistema, assim temos a informação de qual foi a data da carga na tabela e no último step, e o mais importante, é o processo responsável por carregar os dados no DW, Esse step é onde iremos escolher qual tipo será a nossa dimensão, SCD. Para o meu caso, irei escolher o tipo 1, onde o antigo valor do atributo na linha da dimensão é substituído pelo novo valor. Também vamos informar ao Pentaho que o campo SK_PRODUTO será carregado com o valor incremental do próprio banco de dado PostgreSQL.
Feito isso, terminamos de processar todo a nossa dimensão Produto.
Restante das Dimensões
Ainda temos que fazer os processos de mais duas dimensões, sendo elas a dimensão Local de Compra e dimensão Forma de Pagamento, para não ficar muito extenso o texto, nessa etapa vou resumir como fiz cada uma delas de forma mais rápida. Na dimensão de Forma de Pagamento é uma das mais simples, extraímos as informações do nosso banco legado, transformamos os nomes em minúsculo e as letras iniciais maiúsculas e transformar o código em inteiro e fazer a carga no DW. O processo de cada ETL ficou da seguinte maneira:

Na dimensão Local de Compra segue a mesma ideia da dimensão Produto, pois será necessário extrair o tipo de estabelecimento, o endereço, o bairro e a cidade do local de compra do sistema de origem. O processo de cada ETL ficou da seguinte maneira:

Fato Compras
Agora que terminamos de carregar nossas dimensões, vamos para a parte central do nosso projeto, a fato compras, é onde teremos os nossos indicadores, como o valor total, a quantidade comprada e o valor unitário do produto. A modelagem dessa tabela nos mostra que ela recebe os campos Primary Keys das dimensões, que são as ligações para as tabelas dimensões.

Para carregar a nossa tabela Stage, vamos usar a tabela de origem COMPRAS, vemos que essa tabela já temos os códigos PK’s das tabelas Produto, Forma de Pagamento e Local de Compra, vamos usar essas informações para trazer todas as informações da origem e carregar a stage.

Os campos de código recuperados irão servir para buscar no DW a correta surrogate key armazenada no DW. Os campos que recebem os nomes servem para fazer a validação dos códigos recuperado.
Acima é o processo do ETL1, onde temos que, no primeiro step, 1. Extrair do banco de origem, extrair as informações da tabela COMPRAS da origem, nos próximos, 2. Retornar Produto, 3. Retornar Local de Compra e 4. Retornar Forma de Pagamento usa as chaves retornados da tabela de origem COMPRAS para recuperar os códigos e os nomes, o step 5 recupera a data do atual do sistema, assim temos a informação de qual foi a data da carga na tabela stage, o step 6 gera a sequência de apoio para a tabela de stage por onde iremos controlar a atualização da mesma. E por último, o step 7, que faz a carga dos dados vindo dos steps anteriores à ele na tabela stage.
A nossa tabela stage está carregada com os códigos das tabelas de origem, com os campos que servirão como métricas mais a frente e data da compra. Assim precisamos recuperar os códigos do nosso DW e transformar o campo de data da compra em data e o valor total, valor unitário e quantidade comprada.

Como já é de conhecimento, o ETL2 é responsável por transformações dos dados, no primeiro step, 1. Extrai dados stage, extrair os dados da tabela stage carregados no processo anterior, no segundo, 2. Transforma dados, é responsável por tranformar os dados das métricas para númericos e o campo de data, mas por que? Temos que quando carregamos os campos: QTD_COMPRADA_ORIGEM, VL_TOTAL_ORIGEM, e VL_UNITATIO_ORIGEM eles foram carregar como varchar, portanto será necessário transforma eles em Number com casas decimais, no formato 0.00, para que seja possível carregar no banco de dados. Mesmo acontece com o campo DT_COMPRA_ORIGEM, que carregou no formato YYYY/MM/DD, devemos transformar em um campo Date, além disso iremos usar para recuperar a Surrogate Key da tabela dimensão de Tempo.
Os steps, 3. Retorna Produto, 4. Retorna Local Compra, 5. Retorna Forma Pagamento e 6. Retorna Tempo são os steps que retornam as PK’s das tabelas do DW, usando os campos de código extraído da origem, comparando com os campos NK’s das tabelas dimensões, pois são eles os campos referentes aos códigos PK’s do banco de dados de origem. O step 7 recupera a data do atual do sistema, assim temos a informação de qual foi a data da alteração na tabela stage e no oitavo step, é feito o update da tabela com os novos dados transformados nos campos desejados, aqueles sem o _ORIGEM.
Bom, a carga da fato não segue a ideia de SCD, então vamos usar o conceito aqui de fato do tipo Fato Transacional, existe outros tipos, mas para esse caso usaremos esse. A fato transacional é onde será armazenados as milhões de transações que acontece no sistema DW, são geralmente composta por métricas aditivas, ou seja, poderemos fazer somar, por exemplo, por todas as dimensões, podemos ter a visualização de quanto foi a compra no mês de Fevereiro, o valor total comprado do produto Queijo, etc. Então temos os nossos dados já transformados no processo anterior, devemos agora carregar esses dados, aqui vai um levantamento que fiz, a quantidade de dados que temos e teremos no futuro é uma quantidade mínima, então eu irei fazer o delete de toda a tabela Fato e inserir novamente.
Eu não preciso saber o histórico da carga desse dados, então não me importo com o delete de todos os dados antes de inserir novamente os dados, porque eu sei que o sistema de origem manterá a sua consistência. Mas, caso seja necessário no futuro, irei modificar o processo para podermos fazer esse tipo de processo. Outra coisa que é bom mencionar, no futuro poderemos implantar somente o reprocessamento da fato, como isso? Seguinte, usaremos duas variáveis onde receberão a data inicio e data fim, e só vai deletar os dados entre esse intervalo e só inserir dados desse intervalo, é uma opção para caso lá no sistema de origem foi identificado alguns registros inseridos de forma errônea sendo necessário consertar a informação no DW.
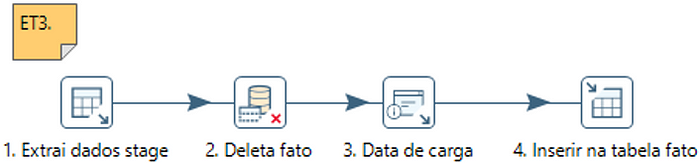
Então temos o processo do ETL3 acima, onde temos que, no primeiro step, 1. Extrai dados stage, os campos já transformados e o seguinte, no step 2. Deleta fato, é feito o delete de toda a tabela, o step 3, 3. Data de carga, recupera a data do atual do sistema, assim temos a informação de qual foi a data da carga na tabela fato e no step 4, 4. Inserir na tabela fato, insere todos os dados na tabela Fato.
JOBS para execução do processo
Feito todo o processo, que o Pentaho chama de Transformations, iremos agora iniciar a criação das Jobs, as Jobs são o que coordena a execução do nosso ETL, então com elas podemos definir o fluxo de execução, preparar a execução com algum processo de checagem antes de iniciar o processo, gerenciamento de arquivos e envio de e-mails de sucesso ou falha. Sabemos, por definição, que a carga das tabelas dimensões deve rodar com sucesso antes de iniciar a carga das tabelas fatos, com a job vamos definir isso. Irei separar aqui em três jobs, sendo eles:
- job_Dimensoes: Aqui iremos criar o fluxo da carga das dimensões e caso ocorra erro iremos enviar um e-mail e abortar todo o processo.
- Job_Fato: Fluxo da carga da tabela fato e caso ocorra erro iremos enviar um e-mail e abortar todo o processo.
- Job_Full: Job responsável por definir a ordem de dimensões primeiro e depois fato e caso ocorra erro iremos enviar um e-mail e abortar todo o processo.
Vou mostrar o Job_dimensoes como fica na ferramenta Pentaho, lembrando que o Job só iniciar o próximo quando acaba de processar o atual, e temos a saída de sucesso e falha, dependendo do resultado do processo atual.

Temos o start que inicia o processo, ele checa as conexões com o banco de dados, caso ocorra algum erro nessa parte, é enviado um e-mail com o log e uma mensagem escolhida para dizer que ocorreu o erro nesse processo de conexão ao banco de dados e todo o processo é abortado.
Caso não ocorra erro, é iniciado a carga das dimensões, iniciando pelo ETL1, depois o ETL2 e o ETL3. Não temos dependência de uma dimensão carregar antes da outra, caso tivéssemos era necessário levantar qual era o nível de cada uma para criar um job adequado. Escolhi que se qualquer uma das cargas desse erro já é para enviar o e-mail e abortar o processo dizendo que o processo de carga das dimensões houve erro. Senão, quer dizer que todo o processo ocorreu com sucesso e dimensões estão carregadas.
O Job_Fato segue a mesma definição. Iniciar o processo checando a conexão com o banco de dados, caso ocorra algum erro nessa parte, é enviado um e-mail com o log e uma mensagem escolhida para dizer que ocorreu o erro nesse processo de conexão ao banco de dados e todo o processo é abortado. Senão é iniciado a carga da tabela fato, caso ocorra erro é enviado o e-mail e abortado o processo. Senão, quer dizer que todo o processo ocorreu com sucesso e tabela fato está carregada.
Por fim, temos o job_full, que é responsável por iniciar cada job acima falado. Nos mesmos moldes dos acima.

Considerações Finais
O processo aqui descrito é um bem simples, mas ele é o que o negócio espera, assim supre as necessidades do negócio e entrega todos os requisitos levantados.
As ferramentas aqui usadas são todas open-source, o banco de dados usado foi o PostgreSQL, a ferramenta de integração de dados é o Pentaho Community e o aplicativo de administração de banco de dados foi o DBeaver. O banco de dados está localizado na nuvem, por meio da empresa Linode. Como é um projeto bem simples, tanto quanto o sistema de origem como todo o DW está hospedado no mesmo servidor. O Pentaho possui um sistema bastante completo, podemos fazer isso com o seu servidor, PDI Server, onde podemos criar cronogramas e horários de execução de todo o ETL, definindo o horário do dia a ser executado e o dia. No futuro irei criar um artigo mostrando como podemos criar todo esse servidor, tanto quanto na nuvem como em on-premise. Como é a primeira versão desse sistema, toda sugestão é sempre vinda e críticas construtivas também.